[Paper Review] DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
A deep dive into DreamBooth (CVPR 2023), a method for personalizing text-to-image diffusion models with just a few subject images.
Note: This is a review of the paper “DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation” (CVPR 2023).
For a Korean version of this review, please visit the OUTTA AI Tech Blog.
Why I Read This Paper
With the explosive growth of Generative AI, especially text-to-image models like Stable Diffusion, the need to inject “my own data” into these models has become significant. It’s not just about generating a dog anymore; it’s about generating “my dog, Poppi.” This is the essence of true personalization in AI.
DreamBooth is a monumental paper that solved this problem with just 3-5 images. It laid the foundation for many subsequent studies, including LoRA. Personally, I found the idea of “Class-specific Prior Preservation Loss” to be incredibly elegant. The methodology of teaching the model the features of a specific instance without forgetting the general concept of the class (preventing Language Drift) was impressive, which led me to read this paper in detail.
Abstract
Large text-to-image models have achieved remarkable success in synthesizing diverse images from text prompts. However, they often lack the ability to mimic the appearance of specific subjects from a given reference set and synthesize novel renditions of them in different contexts.
In this paper, the authors present a new approach for “personalization” of text-to-image diffusion models. Given just a few images (typically 3-5) of a subject, the method fine-tunes a pre-trained text-to-image model to bind a unique identifier with that specific subject. This allows the synthesis of photorealistic images of the subject in diverse scenes, poses, and lighting conditions.
 Figure 1: DreamBooth can synthesize the subject (e.g., a specific dog) in various novel contexts while preserving its key identity features.
Figure 1: DreamBooth can synthesize the subject (e.g., a specific dog) in various novel contexts while preserving its key identity features.
Introduction
The goal of DreamBooth is to expand the language-vision dictionary of a pre-trained model such that it binds new words with specific subjects the user wants to generate. Once the new dictionary is embedded, the model can use these words to synthesize novel photorealistic images of the subject, contextualized in different scenes, while preserving their key identifying features. The effect is akin to a “magic photo booth”.
Large text-to-image models learn a strong semantic prior from large collections of image-caption pairs. For instance, they learn to associate the word “dog” with various instances of dogs. However, they cannot accurately reconstruct the appearance of a specific dog given a few reference images; they usually only create variations of the generic class.
Method
The core idea is to represent a given subject with a rare token identifier and fine-tune a pre-trained, diffusion-based text-to-image framework.
 Figure 2: The DreamBooth fine-tuning process. The model is fine-tuned with a class-specific prior preservation loss to learn the subject instance without forgetting the general class prior.
Figure 2: The DreamBooth fine-tuning process. The model is fine-tuned with a class-specific prior preservation loss to learn the subject instance without forgetting the general class prior.
Class-specific Prior Preservation Loss
A key challenge in fine-tuning on a small set of images is overfitting and language drift (where the model forgets the general class appearance). To mitigate this, the authors propose an autogenous class-specific prior preservation loss.
The method involves:
- Fine-tuning: The model is fine-tuned with the input images and text prompts containing a unique identifier followed by the class name (e.g., “A [V] dog”).
- Prior Preservation: To prevent the model from associating the class name (e.g., “dog”) only with the specific instance, the model is supervised with its own generated samples of the general class. This ensures that the model retains its prior knowledge of the class while learning the specific subject.
Training Details:
- Iterations: ~1000 iterations.
- Learning Rate: $10^{-5}$ for Imagen, $5 \times 10^{-6}$ for Stable Diffusion.
- Data: 3-5 images of the subject are sufficient.
- Time: ~5 minutes on a TPUv4 or NVIDIA A100.
Experiments
The authors created a dataset of 30 subjects (21 inanimate objects, 9 live subjects) to evaluate the method.
Comparison with Baselines
The authors compared DreamBooth with Textual Inversion, another popular personalization method.
| Metric | DreamBooth (Imagen) | DreamBooth (SD) | Textual Inversion (SD) | Real Images |
|---|---|---|---|---|
| DINO (Subject Fidelity) | 0.774 | 0.668 | 0.569 | 0.774 |
| CLIP-I (Subject Fidelity) | 0.815 | 0.767 | 0.726 | 0.880 |
| CLIP-T (Prompt Fidelity) | 0.306 | 0.298 | 0.265 | N/A |
Table 1: Quantitative comparison of subject and prompt fidelity. DreamBooth significantly outperforms Textual Inversion in preserving subject identity (DINO, CLIP-I) and prompt adherence (CLIP-T).
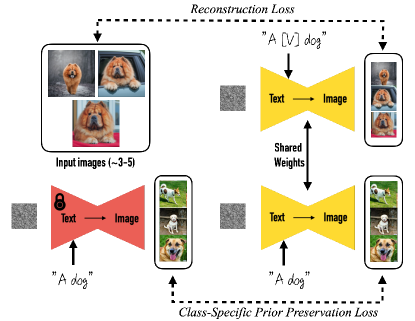 Figure 3: Qualitative comparison. DreamBooth generates images that are more faithful to the subject’s identity and the text prompt compared to Textual Inversion.
Figure 3: Qualitative comparison. DreamBooth generates images that are more faithful to the subject’s identity and the text prompt compared to Textual Inversion.
Evaluation Metrics
- CLIP-I (Subject Fidelity): The average pairwise cosine similarity between CLIP embeddings of generated and real images. This measures how well the subject’s details are preserved.
- DINO (Subject Fidelity): The average pairwise cosine similarity between ViT-S/16 DINO embeddings. The authors argue this is better than CLIP-I for distinguishing unique features of specific objects within the same class.
- CLIP-T (Prompt Fidelity): The average cosine similarity between the text prompt and the image CLIP embeddings. This measures how well the generated image respects the prompt (e.g., “in the Acropolis”).
Conclusion & Insight
DreamBooth is an excellent study that achieved powerful performance with a simple idea (Prior Preservation Loss). In particular, the approach of using “Rare Tokens” to inject new concepts without invading the existing vocabulary space of the model has inspired many researchers since.
From an application perspective, it has high commercial value as it allows users to create their own avatars or profile pictures with just a few photos. Although the need for training time and storage capacity remains a challenge—leading to a preference for more lightweight methods like HyperNetworks or LoRA recently—it is undeniable that DreamBooth was at the starting point of this entire trend.