[Paper Review] Knowledge-enhanced Visual-Language Pre-training on Chest Radiology Images
Review of Knowledge-enhanced Auto Diagnosis (KAD), a model that integrates medical domain knowledge into vision-language pre-training.
Note: This is a review of the paper “Knowledge-enhanced Visual-Language Pre-training on Chest Radiology Images” (Nature Communications 2023).
For a Korean version of this review, please visit the OUTTA AI Tech Blog.
Why I Read This Paper
There have been many attempts to apply Vision-Language Models (VLMs) to the medical AI field, but simply aligning images with text, like CLIP, has clear limitations. In medical data, the relationships between specialized terms (e.g., “Pneumonia”, “Pneumothorax”)—the Knowledge Graph—are crucial.
This paper (KAD) tackles the question, “How can we inject the domain knowledge possessed by doctors into the model?” by taking a direct approach using the UMLS, a massive medical knowledge graph. The result that its Zero-shot performance reached the level of expert radiologists was particularly impressive, making it a must-read for any medical AI researcher.
Introduction
Recent vision-language models (e.g., CLIP) have shown great success in general domains. However, in the medical domain, simply aligning images with raw textual reports is insufficient due to the fine-grained nature of medical tasks and the need for specialized domain knowledge.
This paper introduces Knowledge-enhanced Auto Diagnosis (KAD), a novel framework that integrates structured medical knowledge into vision-language pre-training. KAD leverages the Unified Medical Language System (UMLS) to guide the learning of visual representations, enabling the model to better understand complex medical concepts and relationships.
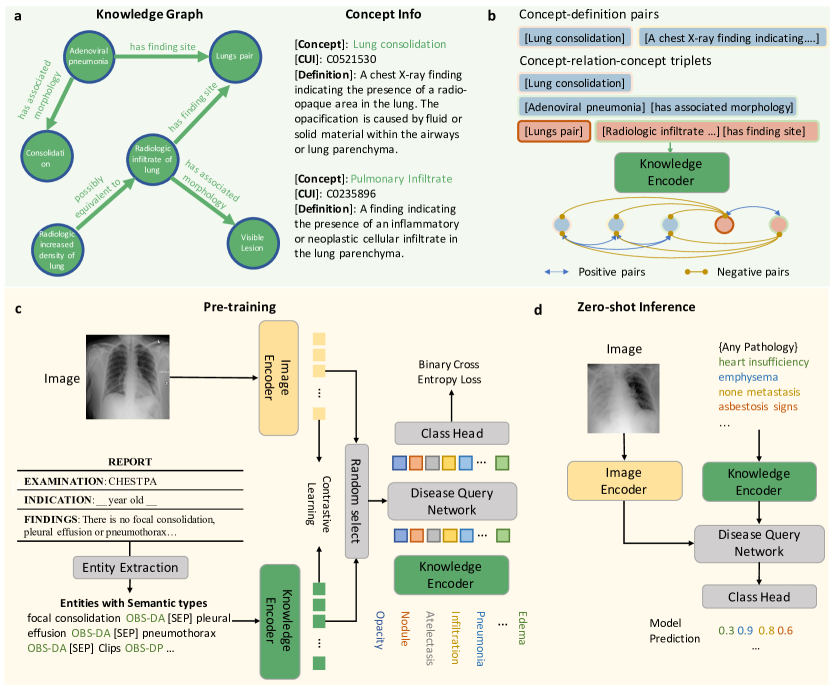 Figure 1: Overview of the KAD framework. It consists of a knowledge encoder trained on a medical knowledge graph and a vision-language pre-training stage that aligns chest X-rays with extracted clinical entities.
Figure 1: Overview of the KAD framework. It consists of a knowledge encoder trained on a medical knowledge graph and a vision-language pre-training stage that aligns chest X-rays with extracted clinical entities.
Methods
a. Knowledge Base & Encoder
The authors construct a knowledge base using UMLS, which contains medical concepts (entities) and their relationships (triplets).
- Knowledge Graph: Represents concepts and their relations (e.g., “Pneumonia” is a finding in “Lung”).
- Knowledge Encoder: A text encoder (based on PubMedBERT) is pre-trained on this knowledge graph using contrastive learning. This ensures that the text embeddings capture the semantic relationships defined in the medical ontology.
b. Image-Text Contrastive Learning
The core of KAD is the alignment of chest X-ray images with radiology reports.
- Image Encoder: Uses ResNet-50 or ViT to extract visual features.
- Entity Extraction: Instead of using raw reports, the model extracts clinical entities and relations using tools like RadGraph or heuristic rules. This filters out noise and focuses on medically relevant information.
- Disease Query Network (DQN): A Transformer-based module that takes a disease name as a query and interacts with the image features to predict the presence of the pathology.
c. Training Objectives
The model is trained with two main losses:
- Contrastive Loss: Aligns the image embeddings with the text embeddings of the extracted entities.
- DQN Loss: A binary cross-entropy loss that optimizes the Disease Query Network for pathology classification.
Results
Performance on Seen Classes
KAD demonstrates superior performance compared to fully supervised baselines (like CheXNet) on standard benchmarks.
| Pathology | CheXNet (AUC) | KAD (AUC) | Improvement |
|---|---|---|---|
| Atelectasis | 0.809 | 0.809 | - |
| Cardiomegaly | 0.916 | 0.916 | - |
| Consolidation | 0.910 | 0.910 | - |
| Edema | 0.966 | 0.966 | - |
| Pneumonia | 0.835 | 0.835 | - |
Table 1: Comparison of AUC scores on PadChest dataset. KAD achieves comparable or superior performance to fully supervised models.
Generalization to Unseen Classes
A key strength of KAD is its zero-shot and few-shot capabilities.
- Zero-shot: KAD achieves impressive performance on unseen pathologies, outperforming expert radiologists in some cases.
- Data Efficiency: In fine-tuning settings with only 1% of labeled data, KAD significantly outperforms existing state-of-the-art models.
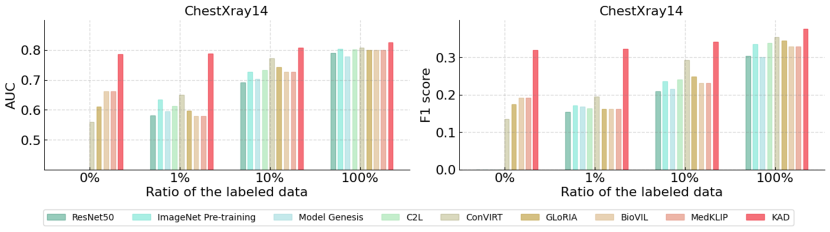 Figure 2: Qualitative results showing the attention maps generated by KAD. The model accurately localizes the pathology (red regions) corresponding to the ground truth (red boxes), providing explainability.
Figure 2: Qualitative results showing the attention maps generated by KAD. The model accurately localizes the pathology (red regions) corresponding to the ground truth (red boxes), providing explainability.
Conclusion & Insight
KAD actively utilizes medical domain knowledge (Knowledge Graph) from the pre-training stage, demonstrating powerful performance even for rare diseases (Long-tail diseases) where data is scarce.
Especially in terms of “Explainable AI (XAI),” the fact that the Attention Map generated by the Disease Query Network aligns well with the actual lesion location will greatly help increase trust in clinical settings. Future medical VLM research will likely focus not just on increasing data volume, but on how to effectively integrate high-quality domain knowledge like this.